Development Approach for Data Engineering & Data Science Projects

Development Approach employed in a Project involving Data Engineering & Data Science
Implementing Engineering fundamentals and best practices when building Solutions that involve Data Engineering and Data science, have more complexity and considerations beyond those required in conventional Application Development. The IDE that ensures the best developer productivity, and how Engineering fundamentals, like ensuring code quality through Unit testing, linting, code coverage checks, are implemented, would differ across the Solution. And in such Projects, it is not just about delivering code in a consistent manner using DevOps, but also about delivering data consistently and repeatably using DataOps, and Machine Learning Models using MlOps.
This article covers one such scenario, and discusses the choices made to implement Engineering Fundamentals and Development Tools to build and deploy the Solution. It also covers alternative approaches considered in the process. It also showcases how the artifacts from across Data Engineering and Data science can be deployed through an end-to-end Integration Testing Pipeline.
Solution Goals and requirements
Before trying to understand the Development approach followed and choice of development tools made, let’s take a look at what the end Solution sought to be built is about. It involves working with incoming data, that comprises of streaming usage Data from Devices, along with periodic, batch data that contains information about applications and configurations in each of the devices. The latter have a bearing on the performance and usage experience on those devices. One of the Design Goals is to use this data to build a Machine Learning Model that predicts the optimal configurations and settings to obtain the best performance in the devices, depending on the nature of workloads in them.
To realise this Solution, development effort is required in the following areas:
Data Engineering
Raw data from upstream systems is continuously pushed to the Landing Zone in Azure Data Lake Store Gen2 (ADLS Gen2). These are compressed files that contain data in csv, ORC formats. Autoloader in Azure Databricks is used to incrementally pick up the incoming files, extract the data in csv, ORC Formats and store them back in ADLS Gen2, as Bronze Datasets. The next stage in the ELT process involves validating the schema of the data before storing them as Silver Datasets. The final stage involves data validation and cleansing before storing as the Gold Datasets. The cleansed data is used as the base for Data Exploration, and Data science work downstream. Data in the Silver and Gold Datasets are stored in Delta Tables.
Data Science
Data Science Engineers use the interactive Data exploration capabilities available in Jupyter Notebooks, to explore the Gold Datasets in ADLS Gen2, merge and filter data in them to identify features that would be useful in the Data science Experiments. These feature Datasets are stored as Delta Tables in ADLS Gen2. Machine Learning Models are authored as Azure Databricks MLflow Experiments, that leverage the Feature Datasets. Jupyter Notebooks are used for the interactive authoring of the experiments, to try out different approaches and techniques before arriving at a Machine Learning Model that provides the optimal results. MLflow is used for tracking the outcomes from across different experiments, and to train, score and store the ML Models in the MLflow Registry.
Development Tools and approach
The architecture used to host the development environment is shown below. Part of the development, particularly in Data Engineering is done directly on Azure Databricks Notebooks, and partly done locally using Visual Studio Code and Jupyter Notebooks. Dev Containers are used to package the development environment as code that can run in Docker Containers on the Developer’s Machine. Inner loop development workflow is followed by which the code written locally is deployed and run inside a Databricks cluster in Azure Databricks Cluster, at development time. The ability to connect to an Azure Databricks cluster from the local development environment is done through the Jupyterlabs integration with Databricks, and also through Databricks Connect.
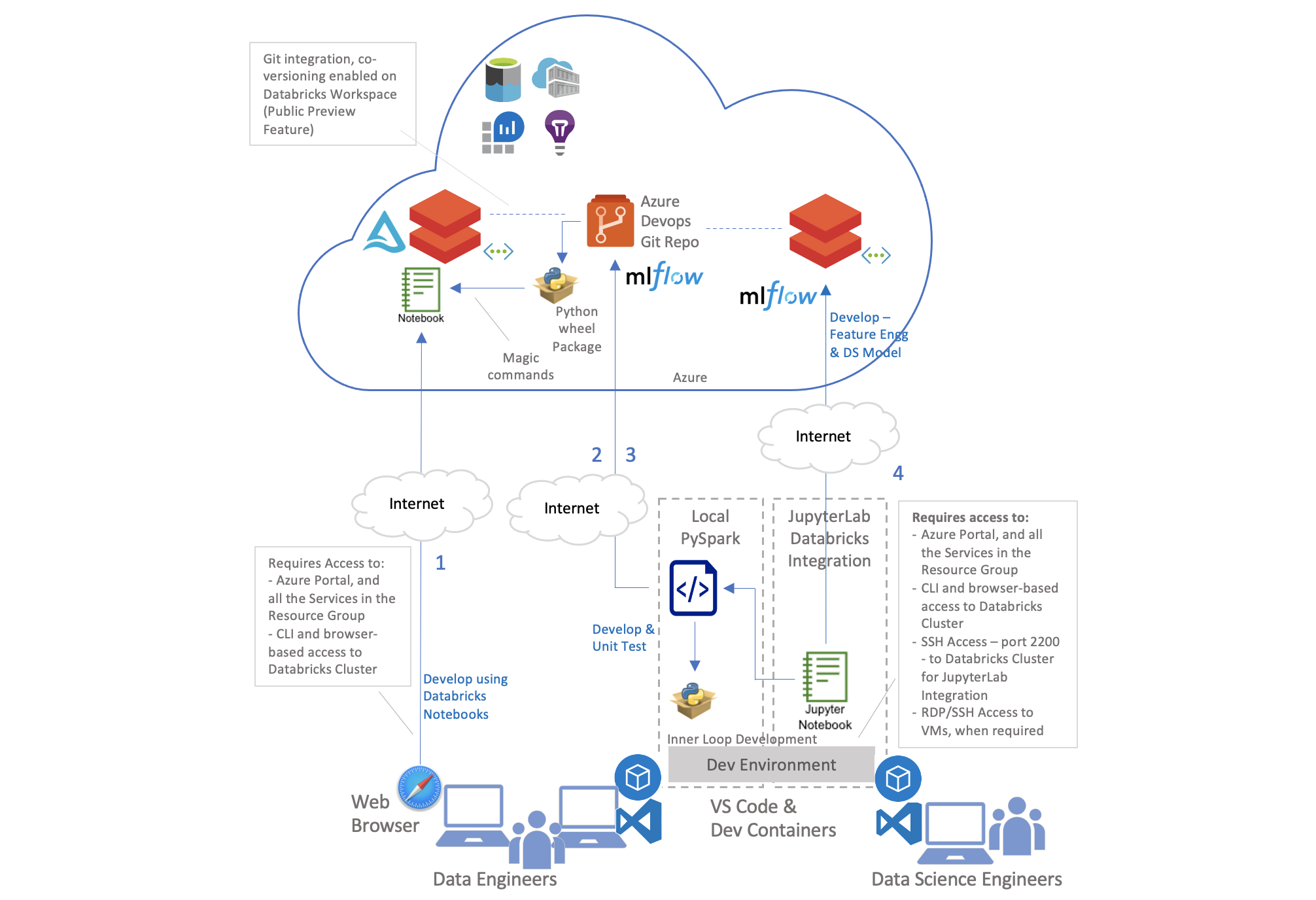
Data Engineering
Development of ELT Pipelines - Azure Databricks Notebooks
The ELT/Orchestration logic that involves read and write of the data in ADLS Gen2 is implemented as Databricks Notebooks (see 1 in the architecture diagram above). Data Engineers would use the web-based IDE in Databricks to implement this functionality. Any reusable logic used across Databricks Notebooks is kept separate and authored as Python code packaged as Wheel and installed at the Notebook level. This is covered in the next sub section.
Source Control Integration:
This Databricks feature in Preview is used to associate an entire Databricks workspace to the Git Repository in Azure DevOps. All Databricks Notebooks in a workspace are co-versioned together, and developers could work on them independently in their own branches.
Code Review, ability to Diff between versions:
Since the Databricks Notebooks are authored as .py files, these can be reviewed as standard Python code, and the reviewer could use the built-in diff feature in Azure DevOps to review the code changes visually, before approval.
Code Linting & coverage:
Since there are no built-in tools in the Databricks Notebook that supports linting, this is instead implemented in Build validation Pipeline in Azure DevOps, prior to the PR getting raised, using tools like Pylint. Code coverage checks are also implemented similarly in the Pipeline, using tools like Cobertura.
Unit Testing:
There is no unit Testing done in Azure Databricks Notebooks, since they only contain orchestration code that deals with reading and writing of data in ADLS Gen2. Instead, the Notebooks are integration tested, end-to-end, using Nutter framework, implemented as a part of the CI Pipeline. How the end to end Integration Testing was done is covered later in this article.
Alternative approaches considered
-
Author the orchestration code in Azure Databricks, then use Databricks CLI to export the source files to VS Code locally, to perform linting and code coverage checks, before publishing to the Git Repository. This approach was relevant when the Git integration features in Databricks did not have the features that are now supported in Public preview, like workspace level integration, complete with all the Databricks Notebooks in them, and the ability to let multiple developers work on their own Feature branches in parallel.
-
Author the orchestration code and reusable business logic in Jupyter Notebooks, and run the Notebook in the integrated Azure Databricks’ kernel from Jupyterlab (a ssh “hook” between Jupyterlab and Databricks). This approach was discarded since it brought in additional complexity for the Data Engineers to deal with. Additionally, the visual code diff feature in Azure DevOps does not support Jupyter Notebooks, and it would have required additional effort to develop a component to cover the Jupyter Notebooks to .py files only for use during code review.
Development of reusable business logic - Python Packages
All reusable business logic like the code used to transform the data, or the code for a generic framework for logging, handling configurations used in the Pipelines are implemented as python code that is packaged as Wheel(see 2 in the architecture diagram above). Data Engineers would use Visual Studio Code on their local machines with Dev Containers to author this logic. The Dev Container uses Conda to manage the Environment for the Python code, along with Spark.
The wheel package is installed in Databricks at the Notebook level, discussed above, at runtime using magicpip commands.
Source Control Integration:
The Python code is developed locally in Visual Studio Code, from where it is checked in to the Git Repository in Azure DevOps
Code Review, ability to Diff between versions:
The reviewer uses the built-in diff feature in Azure DevOps to review the code changes visually, before approval.
Code Linting & coverage:
Linting and code coverage checks are performed locally, using tools like Pylint
Unit Testing:
Done using PyTest, using mock data passed as Spark Dataframes
Data Science
Development of Feature Engineering & ML Model - Azure Databricks Notebooks with MLflow
This is represented as 4 in the Architecture diagram. Data Science Engineers would use the familiar environment of Jupyter Notebooks to author their ML Experiments, locally. It lets them perform adhoc exploration, try out different approaches before identifying the right algorithm, features, and to train, score and evaluate the ML Model that provides the optimum results. There is not much emphasis during this process to follow all Engineering fundamentals, like unit testing, linting, code coverage, etc. All the experiments are authored locally, but the code gets deployed and run in Azure Databricks cluster, through the Jupyterlabs integration with Databricks.
Refactoring of Data Science Code to Python - Azure Databricks Notebooks with MLflow
This is represented as 3 in the Architecture diagram above. Once the Data Science Team has finalised on the MLflow experiment, the code from the experiment is refactored into .py files to be packaged as Wheel. This manual step is performed to ensure that all the Engineering fundamentals are followed on the Experiment code. Note that the other Experiments, created by the Data science Engineers during exploration, are excluded from this exercise.
End-to-end Integration Testing
End-to-end integration testing of Data Engineering and Data science notebooks are performed using Nutter framework using an Azure Devops pipeline. The integration test pipeline performs all the pre requisites for integration testing such as copy notebooks to Databricks workspace, copy configuration files to DBFS, set Databricks cluster environment variables, create MLflow experiments on Databricks etc before running the Nutter test notebook.
End-to-end integration testing uses the following:
- A Nutter test notebook in Databricks workspace that runs Data Engineering and Data Science pipelines and performs assertion on the results.
- An integration test configuration file template that contains input parameters for Data Engineering and Data Science Databricks notebooks, configurations for integration testing such as test directory name, test data path in ADLS Gen2 etc. The template can be updated with variables created during runtime (such as MLflow experiment ID) to create a final integration test configuration file which will be used by the Nutter test notebook.
- Azure Devops variable group that contains Azure environment specific variables such as Databricks cluster ID, host, token, workspace path, DBFS path etc.
- Azure Key Vault can also be used to store secrets such as Databricks token, Personal Access Token to publish and consume Python packages to and from Azure Artifact Feed etc. The secrets are retrieved in the Azure Devops pipeline using the
AzureKeyVault@1task.
Nutter Test Notebook
Nutter framework is used to test Databricks notebooks. A test notebook “test_e2e_integration.py” is created in Databricks. The test notebook contains the following sections:
- Install nutter as a notebook-scoped library
# MAGIC %pip install nutter
- Import NutterFixture base class in test notebook and implement it using a test fixture.
from runtime.nutterfixture import NutterFixture
class TestE2EIntegration(NutterFixture):
...
- before_all(): To perform multiple assertions, a before_all() method is implemented without a run() method. In this pattern, the before_all method runs both the Data Engineering as well Data Science notebooks. There are no run methods.
- assertion_
(): The assertion methods simply assert against what was done in before_all. We can have an assertion method for Data Engineering and Data Science each.
# COMMAND ----------
from runtime.nutterfixture import NutterFixture
class TestE2EIntegration(NutterFixture):
"""Define test suite for end-to-end integration testing."""
def __init__(self, data_engineering_params, data_science_params):
"""Initialize TestE2EIntegration."""
self.data_engineering_params = data_engineering_params.copy()
self.data_science_params = data_science_params.copy()
super().__init__()
def before_all(self):
"""Arrange: Setup test directory structure and data."""
# Drop and create test directory
dbutils.fs.rm(self.data_engineering_params["test_directory"], True)
dbutils.fs.mkdirs(self.data_engineering_params["test_directory"])
# Copy test data for all datasets
dbutils.fs.cp(self.data_engineering_params["test_data_path"], self.data_engineering_params["test_directory"], recurse=True)
# Run Data Engineering notebooks
print("Running Data Engineering notebooks")
dbutils.notebook.run(self.data_engineering_params["notebook"], 0, self.data_engineering_params["input_params"])
# Run Data Science notebooks
print("Running Data Science notebooks")
self.result = dbutils.notebook.run(self.data_science_params["notebook"], 0, self.data_science_params["input_params"])
result = json.loads(self.result)
self.mlflow_run_id = result["mlflow_run_id"]
def assertion_data_engineering(self):
"""Assert data engineering logic."""
def assertion_data_science(self):
"""Assert data science logic."""
# COMMAND ----------
integration_test_config_path = Path("/dbfs/FileStore/libraries/configs/integration_test_config.yaml")
try:
with integration_test_config_path.open("r") as stream:
config = yaml.safe_load(stream)
data_engineering_params = config["data_engineering"]
data_science_params = config["data_science"]
e2e_test = TestE2EIntegration(data_engineering_params, data_science_params)
# Run tests
result = e2e_test.execute_tests()
# Return test results to the Nutter CLI
result.exit(dbutils)
except Exception:
dbutils.fs.rm(data_engineering_params["test_directory"], True)
assert False
End-to-end Integration Test Pipeline
The end-to-end integration test Azure Devops pipeline performs the following activities:
- Create a build version for the python package using Build ID of the pipeline. The python wheel package will be generated using this version.
variables:
- group: integration-test
- name: packageVersion
value: 0.1.0-dev.$(Build.BuildId)
- Run linting and unit tests for the reusable code in python package.
- Publish code coverage and unit test results.
- Build wheel package using the version generated in step 1.
- Publish Data engineering and Data Science Databricks notebooks, corresponding configuration files and python package to Artifact Feed.
The dependencies for the python package are also downloaded to Artifact Feed. This is not visible during the first time upload of the python package. However, when the python package is consumed from the Artifact Feed, the dependencies are automatically downloaded to the Artifact Feed. From here on, anytime the python package is consumed from the Artifact Feed, all the dependencies are downloaded from Azure Artifact python feed rather than the public pypi server.
- Download published artifact from Artifact Feed.
- Deploy Data Engineering, Data Science and Nutter Test notebooks to Databricks workspace
databricks workspace import_dir --overwrite "${source_dir}" "${destination_dir}"
or
databricks workspace import --language PYTHON --overwrite "${source_file}" "${destination_file}"
- Deploy configuration files to DBFS
databricks fs cp --overwrite "${source_file}" "${destination_file}"
- Create MLflow experiment for integration testing
import mlflow
experiment_path = databricks_workspace_path + "/" + experiment_name
experiment = mlflow.get_experiment_by_name(experiment_path)
if experiment is None:
experiment_id = mlflow.create_experiment(experiment_path)
experiment = mlflow.get_experiment(experiment_id)
print("MLflow experiment created successfully")
else:
print("MLflow experiment already exists")
The MLflow experiment ID generated is injected into the integration test configuration template to generate the final configuration file.
sed "s@\$experimentIDPlaceholder@$mlflowExperimentID@g" integration_tests/integration_test_config.template.yaml > integration_tests/integration_test_config.yaml
- Add environment variables (if required) on the Databricks cluster used for integration testing.
updated_cluster_info=$(databricks clusters get --cluster-id "$dataBricksClusterId"| \
jq --arg app_insights_key "$instrumentation_key" \
--arg feed_url "$feed_index_url" \
-c '.spark_env_vars += {"APPINSIGHTS_INSTRUMENTATION_KEY": $app_insights_key, "PIP_INDEX_URL": $feed_url}')
databricks clusters edit --json "$updated_cluster_info"
-
If test data exists in source directory, copy test data to ADLS Gen2 test directory.
-
Install nutter and run integration test notebook through nutter CLI
- bash: |
# Install nutter
pip install nutter
# Execute Nutter test notebook
nutter run $DATABRICKS_WORKSPACE_BASE_PATH/tests/ $DATABRICKS_CLUSTER_ID --recursive --junit_report --timeout 7200
displayName: Run Integration Tests
env:
DATABRICKS_HOST: $(databricksHost)
DATABRICKS_TOKEN: $(databricksToken)
DATABRICKS_CLUSTER_ID: $(databricksClusterId)
DATABRICKS_WORKSPACE_BASE_PATH: $
- Publish integration test results
Conclusion
In this article we have seen how we ensured, during a Data Science project, that Data Scientists and Software Engineers worked hand in hand together. This allowed everyone to keep their ways of working while respecting engineering fundamentals of any development project. In addition, both teams learnt a lot from each others about challenges and constraints of their respective roles.
Contributors to the article
This article is co-authored by: